[Kafka for Dummies - Part 1] Introduction
Posted on 29 March 2019
Big Data is way too hotter than you think. It’s gonna get hotter and show no signs of stopping. One of the biggest challenges associated with Big Data is, turn data into meaningful insights. However before diving into that part, the data has to be first collected then is transfered impeccably in purpose of the availability to the end-users. Hadoop, Spark, Scala, ElasticSearch, … are types of platforms, frameworks and technologies which have emerged to help us handle the ever-growing amount of data over the internet. Among them, Kafka plays an important role. Kafka’s not hard to learn but it has many remarkable theories and concepts. That’s where this series comes in. To those who know nothing about Kafka or wanna revise quickly, my goal is to supply all the basics you need. At the end of the road, you will get a concise overview and apply Kafka easily.
What is Kafka ?
It is a distributed publish-subscribe messaging system that specifically designed for the high-speed, real-time, scalable and low-latency information processing.
Apache Kafka was originally developed by LinkedIn, and was subsequently open sourced in early 2011. Being open source means that It is essentially free to use and has a large community who contributes towards updates and new features.
How does Kafka start?
It looks simple at first: When we have only one data source and one target system.

Things now became really complicated:
Because of new marketing stragety, We need to collect more kind of data and supply for more target systems. It turns out that your project has 4 data sources and 4 target systems. Then we have 16 integrations because they all have to exchange data with one another:
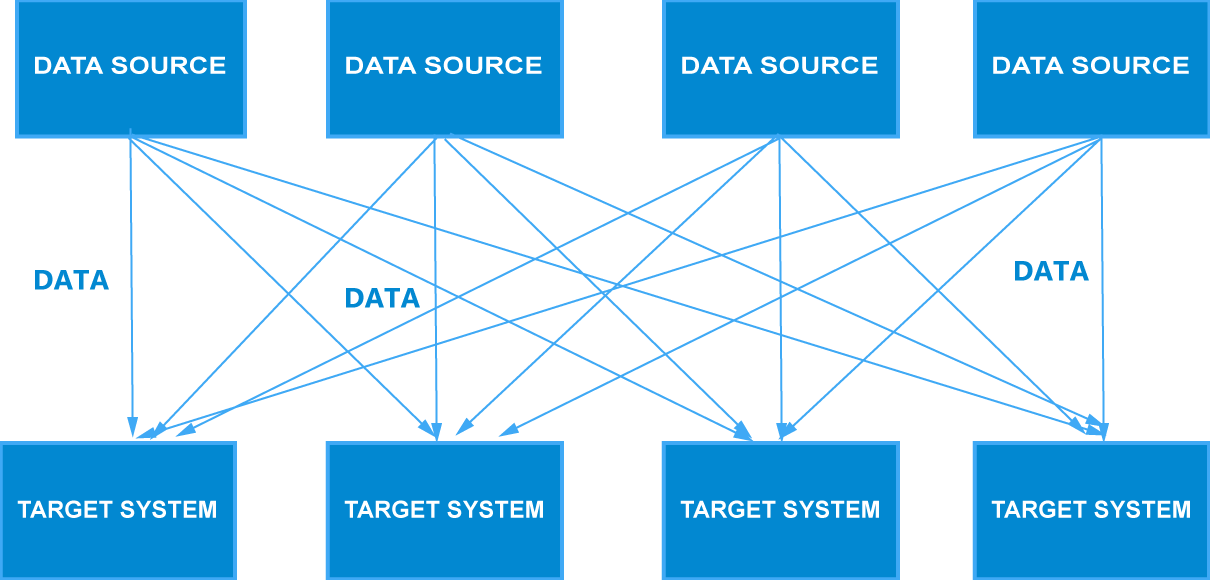
But somewhere down the road, you realize that each integration generate some difficulties:
- - Protocol: How the data is transported ( TCP, REST, ....)
- - Data format : How the data is parsed and extracted ( JSON, CSV, Binary, ... )
- - Data schema & evolution : How the data is formed and may change in the future.
- - Each source system will increased load from the connection
Then, Kafka comes in like the Buddha to solves all the bottlenecks.
It allows to decouple your entry data streams and systems . Now, the source system will push your data into Kafka. While, the target system will source data straight from Kafka. With Kafka’s help, what it enables is really really nice .
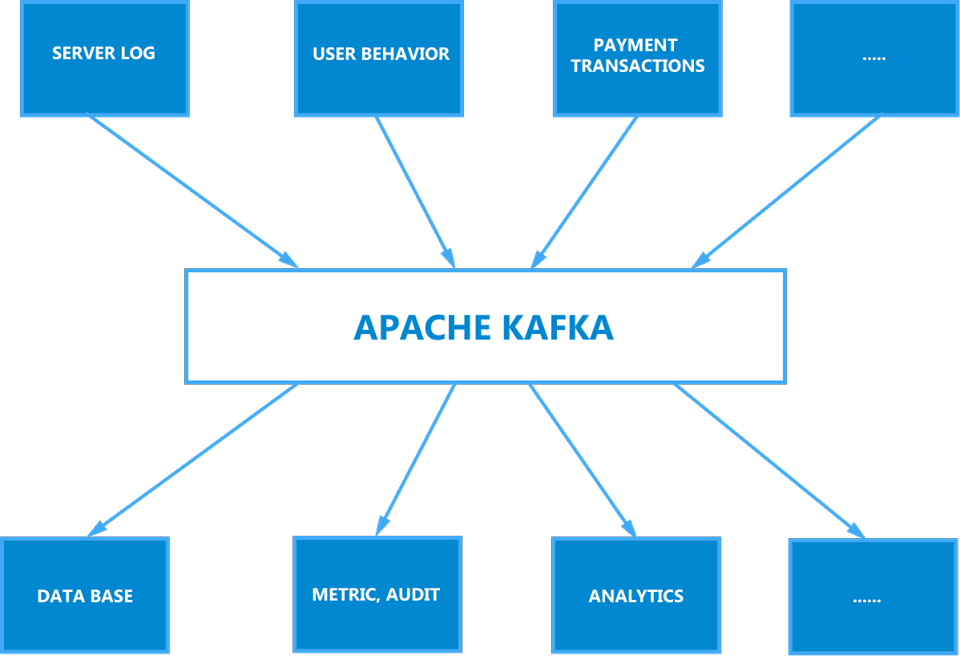
We can have any data sources you can think like SERVER LOG, USER BEHAVIOR, PAYMENT TRANSACTIONS, … . After that, when data is in Kafka, you could put it into any target systems such as DATABASE, METRIC, AUDIT, ANALYTICS, … (above image)
Why would we need to use Apache Kafka ?
Considering its standout:
- - Distributed, resilient architecture, fault tolerant.
- - Horizontal scalability: scale to 100s of brokers and scale to millions of messages per second.
- - High performance (the latency to exchange data from one system to another is usually less than 10ms) and It's realtime.
And its use cases:
- - Messaging System.
- - Activity Tracking
- - Gather metrics from many different locations ( IoT devices )
- - Application Logs gathering
- - Stream processing ( with the Kafka Stream API or Spark for example )
- - De-coupling of system dependencies
- - Integration with Spark, Flink, Storm, Hadoop and many other Big Data technologies.
Can I believe you ?
Don’t believe me. You can believe 2000 plus firms and 35% of the Fortune 500 that uses Kafka as their backbone.
Concrete example:
- - Netflix uses Kafka to apply recommendations in real-time while you're watching TV shows.
- - Uber uses Kafka to gather user, taxi and trip data in real-time to compute and forecast demand, and compute surge pricing in real-time.
- - Linkedin uses Kafka to prevent spam, collect user interactions to make better connection recommendations in real-time.
Rememeber that Kafka is only used as transportation mechanism!
about the author
