Tối ưu hóa cache với LFU và LRU
Posted on 24 July 2019
Tối ưu hóa luôn là vấn đề được quan tâm hàng đầu trong nhiều lĩnh vực. Bởi vì tài nguyên chúng ta đang sử dụng có giới hạn, vậy nên con người luôn tìm cách giảm thiếu chi phí và thời gian tới mức tối thiểu.
Trong lập trình cũng vậy, chúng ta cũng phải đối mặt với vấn đề tối ưu hóa thường xuyên. Thực tế, câu hỏi “Làm sao để tối ưu ?” được đặt ra nhiều hơn khi đi làm so với khi còn ngồi trên ghế nhà trường.
Khi còn ở trường, vấn đề tối ưu đầu tiên tôi gặp phải là tối ưu thuật toán fibonaci. Nếu sử dụng cách đệ quy thông thường thì O(n) sẽ là 2n. Để tối ưu bài toán, có thể cân nhắc đến kĩ thuật memorization giảm chi phí cho bài toán xuống còn O(n) = n. Bản chất đằng sau của thuật toán này là lưu lại các giá trị đã tính trước để phục vụ cho sau này.
Khi đi làm, để tối ưu trải nghiệm của người dùng sử dụng website thì tôi sử dụng cache. Đây là một hệ thống quan trọng để cải thiện hiệu năng của ứng dụng thông qua việc cho phép truy cập và trích xuất dữ liệu nhanh hơn. Mặc dù có khá nhiều ứng dụng cho cache và phụ thuộc vào tính chất công việc, nhưng ý tưởng đằng sau đó khá đơn giản.
Lưu trữ những dữ liệu cần thiết hoặc được sử dụng nhiều trong một "kho chứa" để lần lấy ra tiếp theo sẽ nhanh hơn.
Trong thực tế, cache không nhanh hơn thanh ghi (register) nhưng nhanh hơn nhiều khi so với bộ nhớ chính ( main memory). Để truy cập dữ liệu từ bộ nhớ chính sẽ tốn nhiều thời gian, vậy nên để giảm quá trình này một vùng nhớ đặc biệt trong CPU sẽ được dành riêng chứa một lượng nhỏ dữ liệu cần thiết. Khi một tiến trình muốn tiếp cận lượng dữ liệu trên, đầu tiên nó sẽ kiểm tra trong cache, nếu tìm thấy thì lấy ra và chế biến, nếu không nó mới đi tiếp tới bộ nhớ chính.
Cache phải tuân thủ theo replacement policy khi dung lượng vượt quá giới hạn:
- - Quyết định được dữ liệu nào cần loại bỏ.
- - Tối thiếu được số lượng cache misses.
- - Chi phí thấp.
Có rất nhiều thuật toán implement cache, trong đó có 2 thuật toán đơn giản là Least Recently Used và Least Frequently Used được sử dụng rộng rãi. Và cũng là 2 thuật toán tôi muốn giới thiệu trong bài viết này.
Least Recently Used
Thuật toán này lấy thời gian lần cuối sử dụng object để quyết định có loại bỏ hay không?. Cụ thể, nó sẽ xóa object có thời điểm được sử dụng gần nhất cách thời điểm hiện tại xa nhất khỏi bộ nhớ khi bộ chứa đạt tới giới hạn. Một object vừa được truy cập sẽ được đẩy vào cache hoặc ghi đè thời gian sử dụng nếu đã nằm sẵn trong cache.
Ví dụ: Bạn có một tủ chật kín quần áo và cần bỏ đi vài cái để sắm quần áo mới. Lúc này bạn sẽ loại đi những bộ quần áo mà lần gần nhất bạn mặc cách đây lâu nhất. Để giả định này đúng, do uống trà sữa quá nhiều nên tăng cân, bạn không thể mặc những bộ quần áo cũ mặc dù rất đẹp. Lần cuối mặc nó là lúc chưa tăng cân.
Phân tích cấu trúc dữ liệu:
Để implement được LRU, cần có một data structure đảm bảo được:
| Yêu cầu | Data structure | Chi phí độ phức tạp |
|---|---|---|
| Tìm kiếm | HashMap hoặc HashTable. | O(1) |
| Thêm mới một object | Static array, linked list, Hashmap ( HashTable ) với tỉ lệ collision thấp. | O(1) |
| Xóa object gần nhất sử dụng cách hiện tại xa nhất. | Double Linked list được sắp xếp theo thời gian gần nhất sử dụng tăng dần. | O(1) |
| Hàng đợi ưu tiên ( Priority queue). Cụ thể là Min-heap với key là thời gian gần nhất truy cập của object. | O(logn) | |
| Khi một object đã có trong cache được truy cập thì sẽ ghi đè thời điểm hiện tại vào cache. Đồng thời vẫn đảm bảo vị trí các object theo chiều tăng dần thời gian. | Sử dụng HashMap(HashTable) cho tìm kiếm O(1). Với double linked list thì xóa O(1). Sau đó thêm mới object với thời gian hiện tại là O(1). | O(1) |
| Min-heap như trên. Để đảm bảo tính đúng của Min_heap thì sử dụng heapify cho ta O(logn). | O(logn) |
Với bảng phân tích như trên chúng ta dễ dàng chọn được cấu trúc dữ liệu thích hợp và tốt nhất để xây dựng LRU là : HashMap và Double Linked List.
Implement LRU:
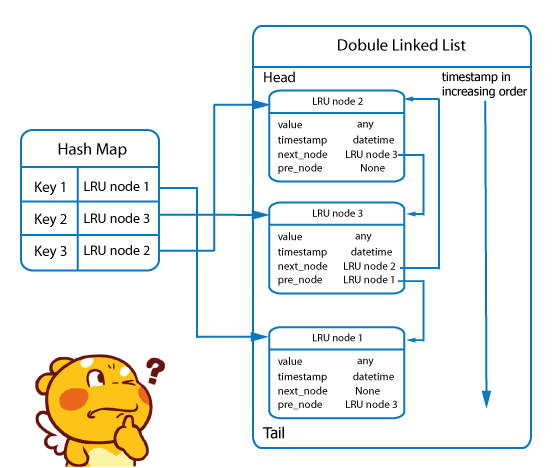
LRU node chứa dữ liệu, thời gian sử dụng và 2 con trỏ tới các node khác.
Hash Map giữ key và LRU node tương ứng.
Double Linked List lưu head là node chứa dữ liệu có thời gian sử dụng cuối cùng xa nhất. Ngược lại, tail sẽ lưu node được sử dụng gần đầy nhất.
Coding LRU:
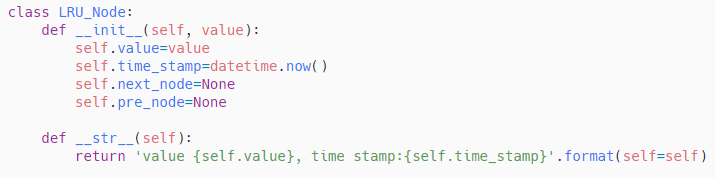
LRU Node
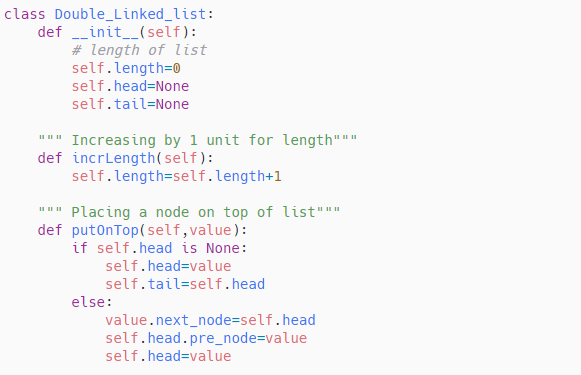
Double Linked List

Đánh giá với implement bằng priority heap:
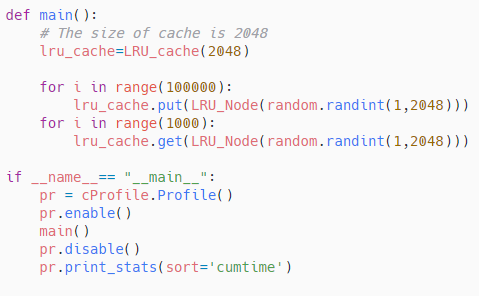
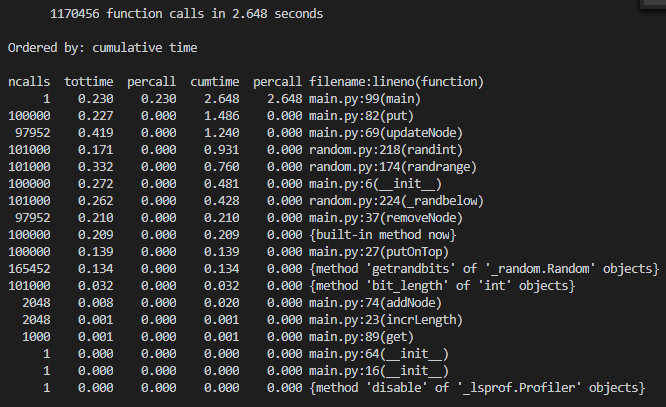
Sử dụng thư viện cProfile để đánh giá hiệu năng.
Cache chứa được 2048 phần tử, giá trị random từ 1 đến 5000, 100000 hành động put và 1000 hành động get.
HashTable + Double Linked List:
Priority Heap:
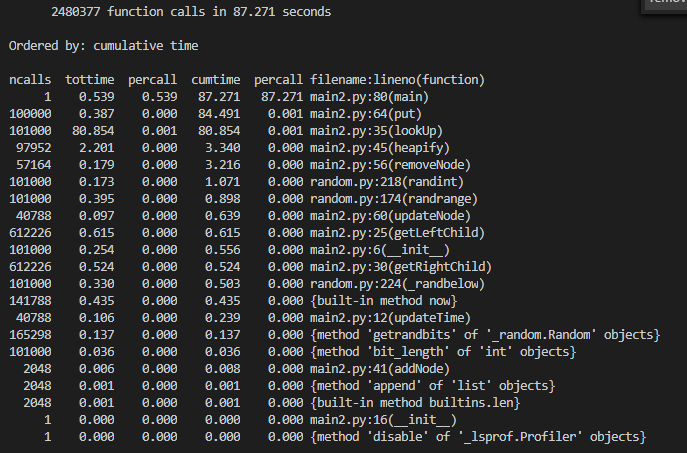
Bỏ thời gian thực hiện random một giá trị cho phần test và các hàm khởi tạo khác. Để khách quan, chúng ta không xét thời gian của hàm tìm kiếm vì với heap sẽ có O(n) ( vì giá trị tìm kiếm không phải là giá trị xây dựng heap ), mà chỉ so sánh thời gian thực hiện hàm xóa và duy trì tính đúng của heap.
| Action | Double Linked List + Hash map | Priority Heap |
|---|---|---|
| removeNode + Heapify(for Heap) | 0.21 | 3.216 |
| updateNode + Heapify(for Heap) | 1.24 | 0.639 |
| addNode | 0.02 | 0.008 |
| Heapify | 0 | 3.670 |
Heapify có độc phức tạp là O(logn). Vậy nên khi so sánh update và remove với HashMap + Double Linked List có O(1) thì thời gian chênh nhau khá lớn. Chỉ tính riêng Heapify đã chiếm thời gian nhiều nhất. Ở bài tiếp theo tôi sẽ giới thiệu Least Frequently Used.
about the author
